|
www.delorie.com/djgpp/malloc/
|
search
|
New Malloc
The Problem
DJGPP's current malloc is fast but not efficient. It is also
restricted by the BSD copyright, which some people object to.
The Project
This page details a number of malloc replacements, and describes
the relative performance and efficiency of each.
The test program simulates a mixed
environment. I don't claim that this is representative of any
application. This is just a simulated suite of calls used to compare
the various mallocs fairly. The test keeps track of elapsed CPU time,
total memory used, and the amount of memory the program thinks it has.
To offset the benchmark overhead, the test0 case uses a set
of dummy routines (malloc0.c) that do nothing
(malloc returns (char *)1, free does
nothing, realloc returns the pointer passed to it). The
results from this test case are saved and used to adjust all other
test cases, so that the time of the benchmark itself is removed from
the results.
Each test case is the result of linking the test program with a
different malloc routine. Each testX uses
mallocX.c. All tests were performed on my 150 MHz R5000 SGI.
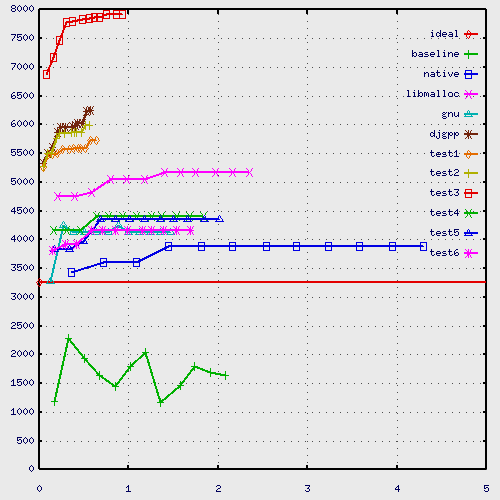
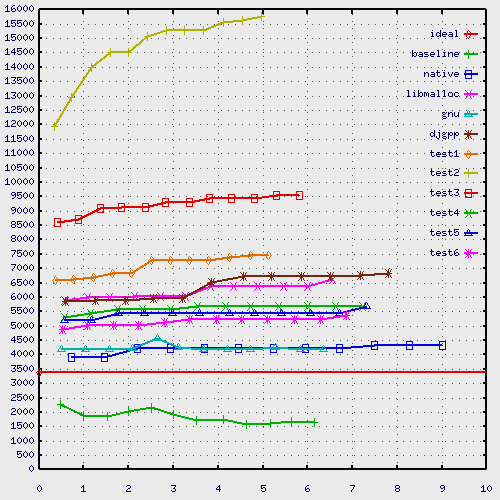
The malloc/free test performs about 600,000 mallocs and 600,000 frees.
- ideal
- Generated from test0, this straight
line indicates the maximum amount of memory the program uses at any
time. This is done by keeping track of the size requested to malloc,
any resizes, and frees.
- baseline
- The results from test0. Note
that the times displayed on the graph are scaled to be somewhat
similar to the other times, so that the viewer can correlate the
memory amounts with the other results. Otherwise, all the times would
be zero.
- native
- This is SGI's native malloc.
- libmalloc
- This is SGI's -lmalloc library.
This one claims to be faster than the regular one.
- gnu
- This is GNU's malloc library.
- djgpp
- This is the malloc that's currently in DJGPP
(BSD's). 2n-4 bytes per small chunk, 2n+4092
for large chunks.
- test1
- Similar algorithm to BSD's malloc, but uses
binary search to find buckets and doesn't pre-allocate small chunks.
Allows exactly 2n bytes in each bucket.
- test2
- Like test1, but uses shift/loop
to find bucket, and pre-allocates small chunks.
- test3
- like test1, but uses 128 buckets
instead of 32 for less waste. Oddly enough, it wastes more because
there's less re-use.
- test4
- This one doesn't use 2n chunks.
Chunks are sized according to the request. We keep the free chunks in
2n-sized buckets to speed up finding them, though. This
algorithm allows for large chunks satisfying small requests (chunks
are split) and for re-combining chunks as they're freed. We also
remember the last big block we split up, so we can use it again, as
well as any extra memory we've got from the last sbrk.
- test5
- test4 with statistics
- test6
- Like test4, but we cache the bucket
number in the free'd chunk, and only compute it when needed. This
version also has a disabled "small request optimizer" that didn't help
my benchmarks, but might help C++ programs. The alignment is 8
instead of 4, and we don't treat the sbrk block at the end of memory
specially (it was used rarely, but we still had to check it each
time).
The Results
The X axis is the number of elapsed seconds (minus the baseline
time). The Y axis is kilobytes of core used (sbrk() change).
| malloc/free |
malloc/realloc/free |
|---|
 |
 |
The Sources